Intro
Many people say that ggplot is a powerful package for visualization in R. I know that. But i’d never triggered to explore this package deeper (except just to visualize mainstream plot like pie chart, bar chart, etc.) till this post impressed me.
That post is about plotting map using ggplot. The pretty plots resulted on that post challenged me to explore ggplot more, especially in plotting map/spatial data.
Preparation
We always need data for any analysis. The author of those post use USA map data available in ggplot2 package. Though that post is reproducible research (data and code are available) menas i can re-run the examole on my own, but I want to go with local using Indonesia map data.
So, objective of this post is to visualize Indonesian population by province in Indonesia. So we need the two kinds of dataset. First is population data in province level and second is Indonesia map data.
The first data is available in BPS site. The data consists of population density (jiwa/km2) for each province in Indonesia from 2000 till 2015. I will go with the latest year available on the data which is 2015.
Oke, now we arrive to the hardest part. I stacked for a while when searching Indonesia map data that suit for ggplot2 geom_polygon format. But Alhamdillah, after read some articles about kind of spatial data, I got one clue, I need shape data with .shp format to plot map data. And just by typing “indonesian .shp data” on google, He will provide us tons of link results. Finally, I got Indonesian .shp data from this site. I downloaded level 1 data (province level) for this analysis.
Data Acquisition
The fist step is load data into R. I use rgdal package to import .shp data. rgdal is more efficient in loading shape data compared to others package like maptools, etc.
1
2
3
4
|
#import data .shp file
library("rgdal")
#import .shp data
idn_shape <- readOGR(dsn = path.expand("/YOUR_PATH/IDN_adm"), layer="IDN_adm1")
|
Here’s one of the advantages using rgdal package, though it is in shape format we can use operation like names(), table(), and $ subset operation like in data frame format.
After data loaded into R workspace, we need to reformat shape data into format that suit to ggplot2 function.
1
2
3
4
|
#format data
library("ggplot2")
idn_shape_df <- fortify(idn_shape)
head(idn_shape_df)
|
1
2
3
4
5
6
7
|
## long lat order hole piece id group
## 1 96.23585 4.055532 1 FALSE 1 0 0.1
## 2 96.23552 4.055860 2 FALSE 1 0 0.1
## 3 96.23448 4.056840 3 FALSE 1 0 0.1
## 4 96.23372 4.057950 4 FALSE 1 0 0.1
## 5 96.23324 4.058574 5 FALSE 1 0 0.1
## 6 96.23248 4.059689 6 FALSE 1 0 0.1
|
data will look like above table.
Next step, we will try to visualize the data we already have
1
2
3
4
|
#visualize as in data
ggplot() +
geom_polygon(data = idn_shape_df, aes(x=long, y = lat, group = group)) +
coord_fixed(1.3)
|
It works!, my data has suitable for ggplot2 format. Let’s make it more colorful by colorize each province.
1
2
3
4
5
|
#add color by province
ggplot(data = idn_shape_df) +
geom_polygon(aes(x = long, y = lat, fill = id, group = group), color = "white") +
coord_fixed(1.3) +
guides(fill=FALSE) # do this to leave off the color legend
|
Cool! looks much better. But that’s not the goal of this analysis. Let’s moving forward. Now need to add population density data to complete the analysis.
1
2
3
4
|
#import density data
population <- read.csv("/Users/Muhammad Idrus F/Downloads/bps-file.csv", sep=";")
population <- population[,c(5,6)] #put only needed variable
head(population)
|
to make it more intuitive, let’s change the column name with what it should be.
1
|
colnames(population) <- c("density", "provinsi")
|
population data has two column; provinsi and density with 34 rows fit to the number of province in Indonesia from Aceh to Papua. Next, we need to merge population dataset with idn_shape_df dataset. If you look in idn_shape, the id column in idn_shape dataset represents the province name. So, the id column in idn_shape_df should represents province name too. Then value in id column better we replace by province name.
1
2
3
|
#we need to creat dict of province id first
dict_prov_id = data.frame(idn_shape$ID_1, idn_shape$NAME_1)
colnames(dict_prov_id) <- c("id", "provinsi") #rename the column name
|
Before we join, we notice that id index on idn_shape_df somehow start from 0 while id index on idn_shape. We need transform id on the two tables to be identical.
1
2
3
|
idn_shape_df$id <- as.integer(idn_shape_df$id) + 1 #transform id value to be similar with id on idn_shape table due to different initial index
idn_shape_df$id <- with(dict_prov_id, provinsi[match(idn_shape_df$id, id)])
head(idn_shape_df)
|
1
2
3
4
5
6
7
|
## long lat order hole piece id group
## 1 96.23585 4.055532 1 FALSE 1 Aceh 0.1
## 2 96.23552 4.055860 2 FALSE 1 Aceh 0.1
## 3 96.23448 4.056840 3 FALSE 1 Aceh 0.1
## 4 96.23372 4.057950 4 FALSE 1 Aceh 0.1
## 5 96.23324 4.058574 5 FALSE 1 Aceh 0.1
## 6 96.23248 4.059689 6 FALSE 1 Aceh 0.1
|
Now shapefile data idn_shape_df are ready. Next let’s join it with Indonesia’s population data we get from BPS.
Since we have replaced value in id column by province name, it’ll be better if we also rename the id column name into provinsi. Then, we will merge population dataset with idn_shape_df using inner_join from dplyr package.
1
2
3
4
5
6
7
8
9
10
11
|
#rename id column with provinsi
colnames(idn_shape_df)[6] <- "provinsi"
#make value in provinsi column to lower to avoid case sensitive
idn_shape_df$provinsi <- tolower(idn_shape_df$provinsi)
population$provinsi <-tolower(population$provinsi)
#join the two datasets
library(dplyr)
idn_pop_density <- inner_join(idn_shape_df, population, by = "provinsi")
head(idn_pop_density)
|
1
2
3
4
5
6
7
|
## long lat order hole piece provinsi group density
## 1 96.23585 4.055532 1 FALSE 1 aceh 0.1 86
## 2 96.23552 4.055860 2 FALSE 1 aceh 0.1 86
## 3 96.23448 4.056840 3 FALSE 1 aceh 0.1 86
## 4 96.23372 4.057950 4 FALSE 1 aceh 0.1 86
## 5 96.23324 4.058574 5 FALSE 1 aceh 0.1 86
## 6 96.23248 4.059689 6 FALSE 1 aceh 0.1 86
|
idn_pop_density is the final data that will we visualise using ggplot2.
Visualise Indonesia map data
Time to the main part of this analysis, plotting the density map.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
#need this to remove background and outline of graph
ditch_the_axes <- theme(
axis.text = element_blank(),
axis.line = element_blank(),
axis.ticks = element_blank(),
panel.border = element_blank(),
panel.grid = element_blank(),
axis.title = element_blank()
)
#plot the map
map_pop_density <- ggplot(data = idn_shape_df, mapping = aes(x = long, y = lat, group = group)) +
coord_fixed(1.3) +
geom_polygon(aes(x=long,y=lat, group=group, fill=density), data=idn_pop_density, color='black') +
geom_polygon(color = "black", fill = NA) +
theme_bw() +
ditch_the_axes
map_pop_density
|
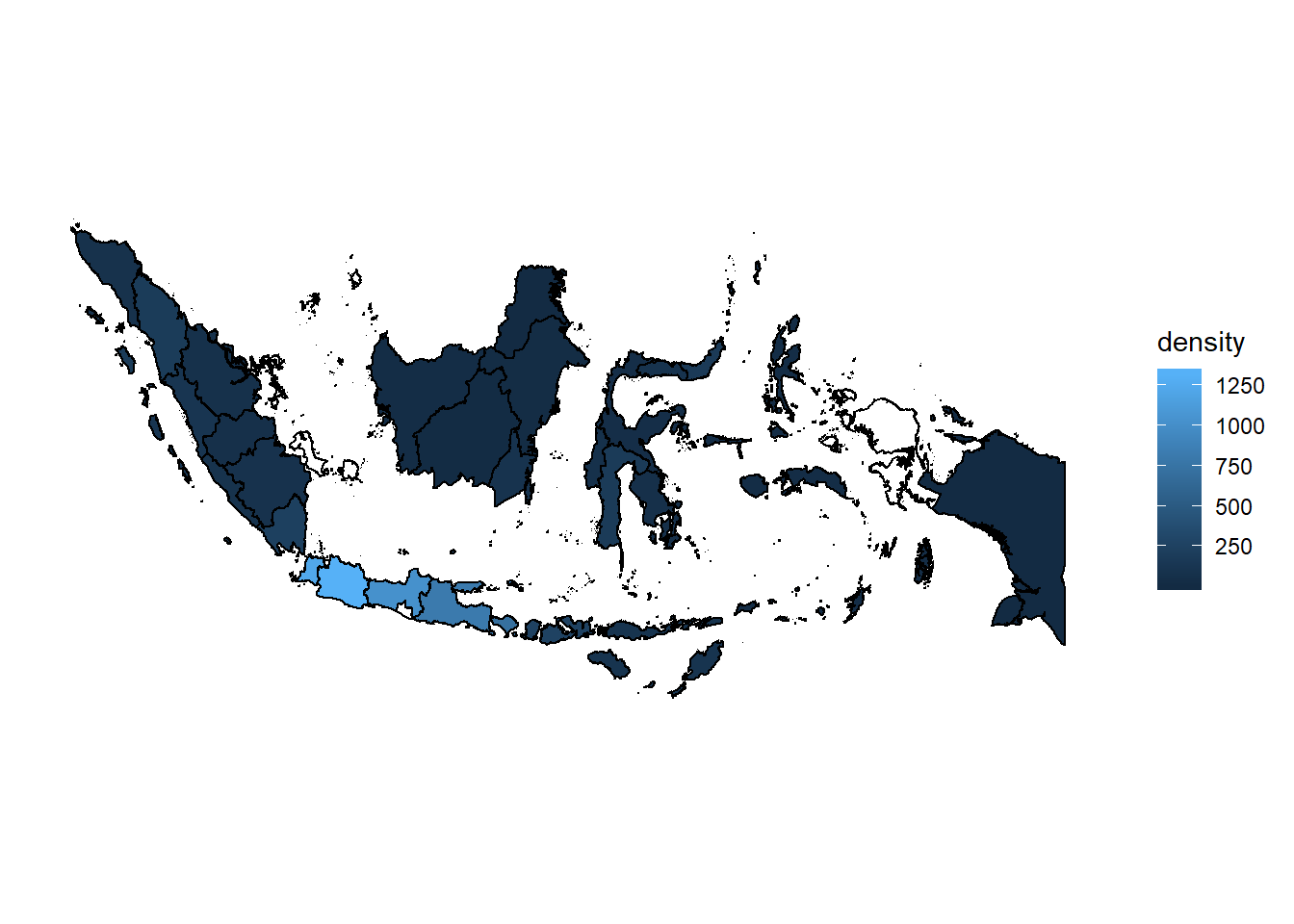
Final touch
Cool! but it looks like it’s hard to discern the different in area. Let’s make it clearer by transforming the value of density by log10 , reseve the density color to make the more dark color indicate the more dense area also change legend title.
1
2
3
|
map_pop_density + scale_fill_gradient(trans = "log10",
high = "#132B43", low = "#56B1F7",
name="jiwa/km2")
|
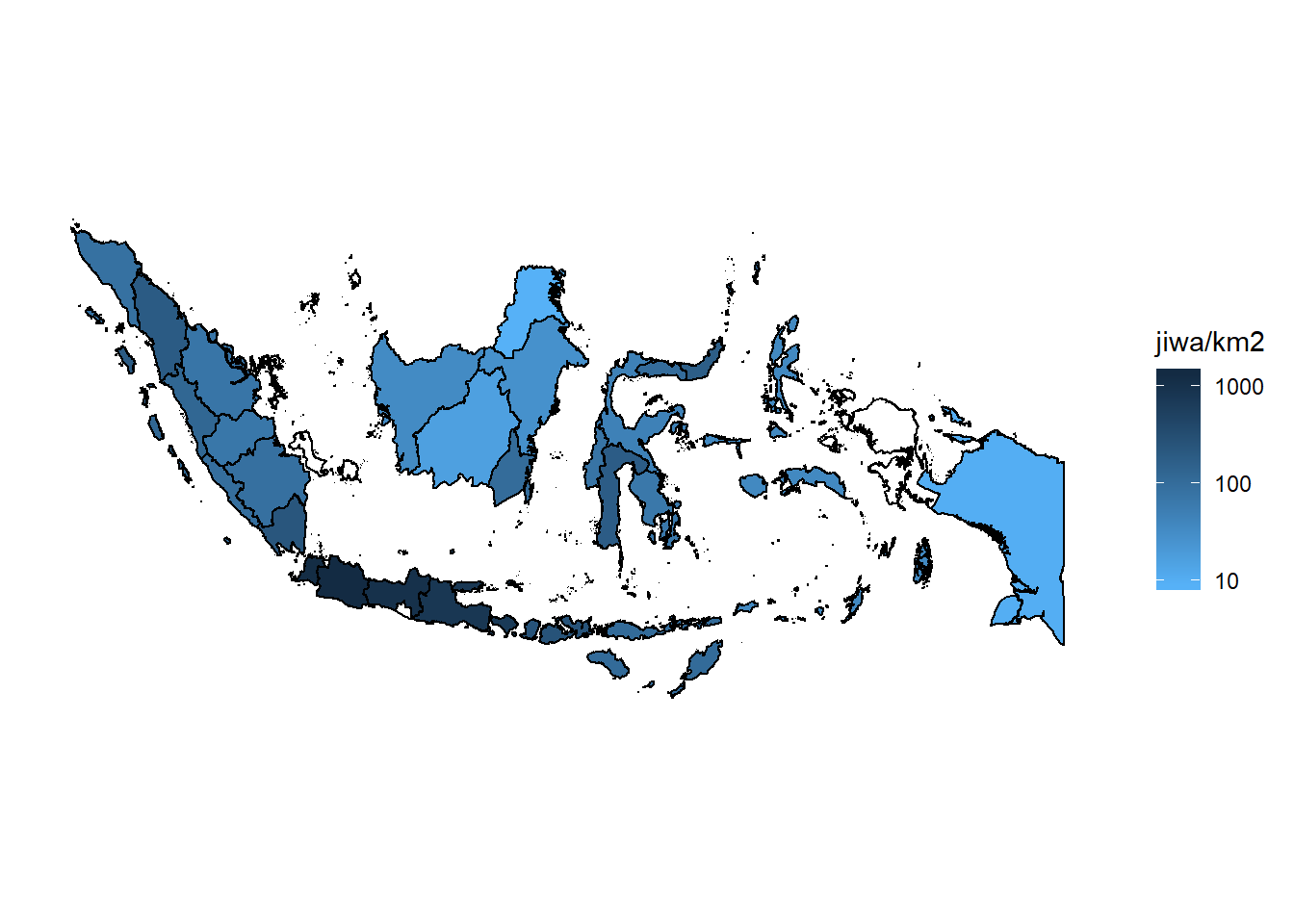
Looks better now. Nothing special with the data as we know that Java has very high population compared to others province/area in Indonesia, and we are not discussing about that point this time. This is just an example of how to visualise map/spatial data especially for Indonesian area using R which is open source (free) tools instead of using paid tools. We can then replace the fill by others value like number of sufferer of certain desaese to map the its spreadness or others data we desire.
Note : If you notice there are some provinces that has white color, It’s because the province name on data from BPS and .shp file has different value. So when we join that two tables by province name, some rows doesn’t match. For example Kep. Riau and Kepulauan Riau, Papua Barat and Irian Jaya Bara, Bangka-Belitung and Bangka Belitung. It needs further processing to handle this may be using regex join etc. But i won’t cover that on this post.
Refference:







